メモ帳の文字化けの仕組み【開発者による解説】
- 作成日: 2025-11-03
- 更新日: 2026-03-18
- カテゴリ: メモ
- タグ: メモ帳, 文字化け, 仕組み
またかよ!また文字化けかよ!おいおい!どうなってんだよぉ(泣。
・・・こんなご経験はないでしょうか?
メモ帳でファイルを開いたら文字化け・・・。何度開きなおしても文字化けしている・・・。
もしかして文字化けについて詳しくなりたいのではないでしょうか、あなたは。
それではソフトウェア開発者のわたくしが、じっくり、簡潔に解説させていただきたいと思います。
この記事を読めば寿命が延びるとか、体重が減るとか、そんなことはありません・・・。
しかし文字化けについては少し詳しくなれるかも、しれません。
※この記事はプロモーションを含みます。
文字化けの仕組み
ファイルとは
文字化けについて解説する場合、まず「ファイル」とはなんなのかを解説しなければいけません。
パソコンにおけるファイルとは、ディスクの特定の場所に付けるラベルみたいなものです。
ディスクと言うのはハードディスクとか、SSDとか、データを保存するあれです。
そのディスクにデータを保存するときにラベルを付けます。
ラベルを付けるとディスクのここからここまではこのデータ、という風に管理することができます。
このラベルを含めたデータ領域がファイルと呼ばれています。
ファイルの中身
パソコンというのはデータは実は0と1しか理解することができません。
これはハードディスクでは「磁化(じか)」というもので表現されます。
磁化というのはパターンがありN極とS極があります。
この2つのパターンでデータの0と1をディスクに記録してデータを保存します。
つまりファイルというのも、ディスクには磁化で保存されているもので、それが日本語のテキストとして変換されて表示されているわけです。
バイト列
データはパソコンでは0と1で表現しています。
この0と1の2通りを表す単位を「ビット(bit)」と呼びます。
ビットは0と1のどちらかになる電灯みたいなものです。
さらにこのビットが8つ集まると「バイト(byte)」と呼びます。
このバイトが集まっている列を「バイト列」と呼びます。
ディスクにN極とS極で保存されていた0と1のデータは、パソコンで扱う場合はビットになり、さらにそれをまとめてバイトとして扱うわけです。
そしてファイルと言うのは通常はこのバイトでデータを扱います。
バイトはビットが8つ集まったものなので、0と1の表現が8通りあることになります。
つまり数学的に言うと2の8乗になり、表現できる組み合わせは256通りになるわけです。
つまり1バイトあれば0から255までの数値を表現できるということになります。
文字
パソコンの文字は前述のバイトやバイト列で表現されています。
ではどういう風に文字を表現するのでしょうか。
バイトは0から255までの数値を表現できます。
ですので、数値に文字を対応させれば、数値から文字、文字から数値に変換できるわけです。
この文字と数値の対応を「文字コード」と呼びます。
ASCIIコード(アスキーコード)という文字コードでは、「A」という文字は数値の「65」に対応します。
「Z」は数値の「90」です。「a」は「97」で、「z」は「122」です。
ということでアルファベットだけなら1バイトで表現できるわけです。
日本語の文字
しかし1バイトは0から255までの数値を表現できますが、それだけでは日本語は表現できません。
日本語は漢字も含めると数千以上の文字があるからです。
そこで複数のバイトを繋げて、そのバイト列で1つの文字を表現するというアイデアが生まれました。
しかし問題は、そのアイデアを思い付いたのが1人だけではないということでした。
結果として、日本語の文字を表現する文字コードは無数に生まれました。
Shift-JIS, EUC-JP, UTF-8など。
これらはみな違う文字とバイト列の対応を持っています。
ファイルと文字コード
ファイルにデータを記録する場合、この文字コードが問題になります。
文字コードはみな違う文字とバイト列の対応を持っているわけです。
ですので、Shift-JISで保存したファイルと、UTF-8で保存したファイルとでは、中身のバイト列が違うわけです。
メモ帳はファイルを開いて中身を表示する場合、Shift-JISならShift-JISの文字コードで数値を日本語に変換しないといけません。UTF-8ならUTF-8です。
では、この書き込んだ文字コードと表示した文字コードが違っていた場合どうなるでしょうか?
ここまで解説すると、なんとな~くわかってくる人もいるかもしれません。
実はそうなんです。
文字化けは文字コードの違いで起こる
たとえばShift-JISの文字コードで保存したファイルがあります。
ではこのファイルをUTF-8として開いたらどうなるかというと、文字化けします。
これはShift-JISとUTF-8では文字と数値の対応の文字コードが違っているからです。
「あ」という文字1つを表すとしてもShift-JISとUTF-8では、中身の数値が変わってきます。
これが文字化けの仕組みです。
では文字化けを直すにはどうしたらいいのか?
文字化けを直すには、保存されているファイルのデータに合っている文字コードでファイルを開くことです。
保存に使った文字コードと表示に使う文字コードが合っていればちゃんと文字化けせずに表示できます。
ただし、これは例外があります。それは文字化けしたデータを別のファイルに保存した場合です。
この場合、文字化けしたデータをさらに別の文字コードで保存することになります。
こうなると、元の文字コードで開きなおしても文字化けしたままです。
なぜかというと数値に対応させている文字がそもそも文字化けしているからです。
【PR】文字化けの判別に使えるソフトは?
ここから宣伝になります。
当サイトが開発した「文字化けチェック侍」です。
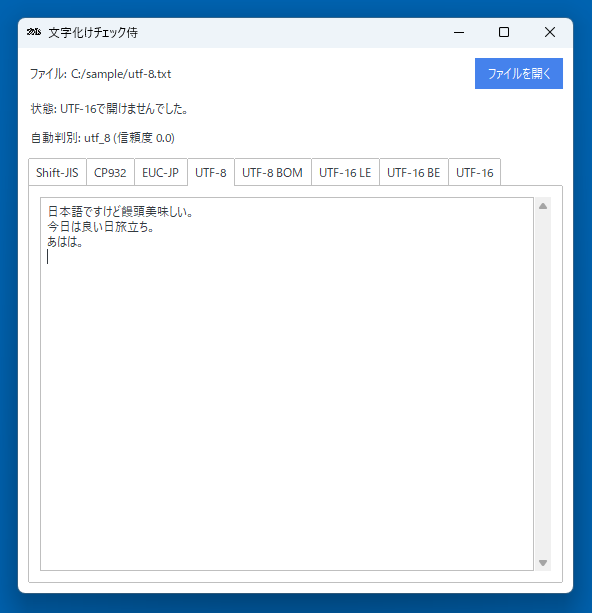
文字化けチェック侍は、テキストファイルの文字コードをチェックできます。
複数の文字コードでプレビューすることができ、ファイルをちゃんと開ける文字コードを確認できます。
また自動判別機能もあり、これで文字コードを自動判別することもできます。
対応OSはWindows11(x64)です。
ぜひダウンロードしてみてください。
おわりに
今回はメモ帳の文字化けの仕組みを解説しました。
文字は数値で表現されていて、文字化けはその文字と数値と対応が合っていないから、ということでした。
では、ここまでお読みいただきありがとうございました。